Sentiment analysis with SQL and AI in BigQuery
Use SQL to access pre-trained AI models like Gemini so you can do sentiment analysis and other natural language processing tasks.


Intro
"Are we listening to our users? How?"
It's a question product managers ask all the time. The answer is usually something like, "we're listening, but it's a work in progress."
That's because listening is hard at every step. It's hard to ask the right questions at the right time. It's hard to match feedback to a user's unique experience. And it's hard to analyze feedback, identify meaningful trends, and rally stakeholders around actionable insights.
AI cannot do all the work for you, but AI can help. Today, using AI is easier and cheaper than ever before.
In this post I'll show you how to use SQL in BigQuery to analyze free response feedback using AI models like Gemini Pro and Google's Natural Language API. It only takes about 10 lines of code.
This post isn't meant to be a final answer for how you should do sentiment analysis where you work, but rather a jumping off point to help you access AI models and do NLP through prompts in BigQuery.
👉 Here is a follow up post on how to use local LLMs to do NLP on sensitive data.
The result
The SQL shared in this article will generate a result that looks like this.
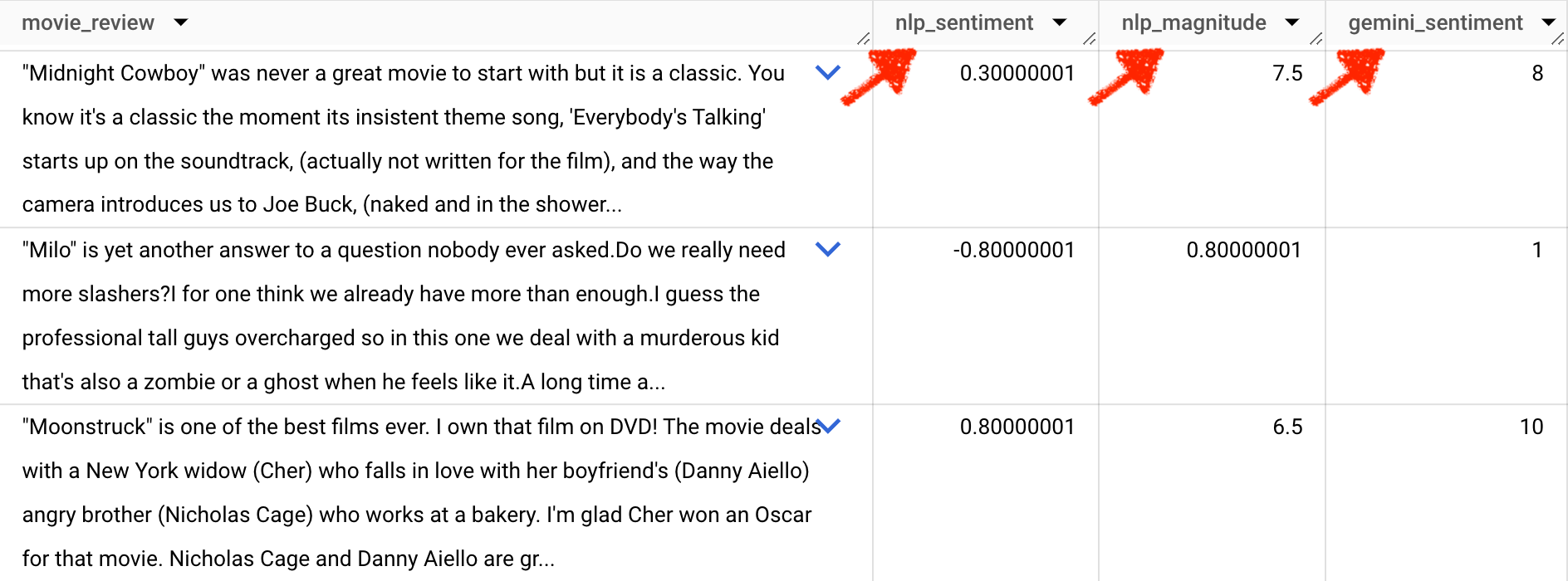
nlp_sentiment - the "emotional opinion" represented through the movie review, on a scale of -1 (negative) to 1 (positive), using Google's Cloud Natural Language API
nlp_magnitude - the intensity of the sentiment on a scale of 0 to 1, using Google's Cloud Natural Language API
gemini_sentiment - the sentiment represented by the movie review, on a scale of 1 to 10, as determined by a prompt sent through Gemini Pro
We'll get into interpretation of the result in the sections below.
Before you run the code
- Read the section: How the code works
- Running this code will cost you about $0.05, or roughly $1 for every 1,000 requests. Using AI models in Google Cloud is not free.
- You need to set up payment, connections, and a service account with appropriate permissions to run this code. If you haven't done this you will hit errors. (I might explain in an upcoming article how to get set up, but the official docs are pretty useful.)
- Beware leaking personally identifiable information (PII) into AI tools. That's not a problem in the demo provided below because it uses data in the public domain. If you're using proprietary data, get approval from your manager and use good judgement before using BigQuery and LLMs that you don't host yourself.
The code: SQL for Sentiment Analysis
See the code below. Add it to your BigQuery console and replace what's in brackets.
-- Isolate your natural language data
CREATE OR REPLACE TABLE `[project].[dataset].[table]` AS
SELECT review, movie_url, label, reviewer_rating
FROM `bigquery-public-data.imdb.reviews`
WHERE reviewer_rating IS NOT NULL AND RAND() < 0.001;
-- Create a remote model
CREATE OR REPLACE MODEL `[project].[dataset].[model_name_a]`
REMOTE WITH CONNECTION `[dataset].[location].[dataset]`
OPTIONS (REMOTE_SERVICE_TYPE = 'CLOUD_AI_NATURAL_LANGUAGE_V1');
-- Run the data through your model to extract sentiment
CREATE OR REPLACE TABLE `[project].[dataset].[table]` AS
SELECT *, float64(ml_understand_text_result.document_sentiment.score) as sentiment_score, float64(ml_understand_text_result.document_sentiment.magnitude) as magnitude_score,
FROM ML.UNDERSTAND_TEXT(
MODEL `[project].[dataset].[model_name_a]`,
(SELECT review AS text_content, movie_url, label, reviewer_rating from `[dataset].[table]`)
STRUCT('analyze_sentiment' AS nlu_option));
How the code works
First, isolate your natural language data
CREATE OR REPLACE TABLE `[project].[dataset].[table]` AS
SELECT review, movie_url, label, reviewer_rating
FROM `bigquery-public-data.imdb.reviews`
WHERE reviewer_rating IS NOT NULL AND RAND() < 0.001;You can use any data you like, but in this example we query the publicly available IMDB movie reviews dataset which contains 100,000 real movie reviews. We duplicate a sample of the public data and save it in our dataset to use and modify throughout this analysis.
A couple notes:
WHERE reviewer_rating IS NOT NULL - We only want reviews that include a 0-10 score, because we'll use that to assess the accuracy of our final result.
AND RAND() < 0.001 - And we only want a small fraction of the reviews – this will return about 47 results – because it costs about $1 for every 1,000 requests to a connected AI model.
Create a remote AI model
CREATE OR REPLACE MODEL `[project].[dataset].[model_name_a]`
REMOTE WITH CONNECTION `[dataset].[location].[dataset]`
OPTIONS (REMOTE_SERVICE_TYPE = 'CLOUD_AI_NATURAL_LANGUAGE_V1');These days you don't need to know Python or train your own models to do machine learning. Now you can access models right out of the box with a few lines of SQL in the BigQuery console. (You can also train your own models with SQL, but that's a post for another time.)
With this code we create a connection to a pre-trained model – Google's Cloud Natural Language API – and save that connection in our project so we can access the model with SQL. The Natural Language API is one of many pre-trained models we can access in BigQuery. We'll also create a connection to Google's state-of-the art LLM Gemini Pro, which you'll see in a section below. But the NLP API is Google's standard model for sentiment analysis (you don't need to write a prompt), and it does other cool things like entity extraction and "moderation" to detect sensitive or offensive content.
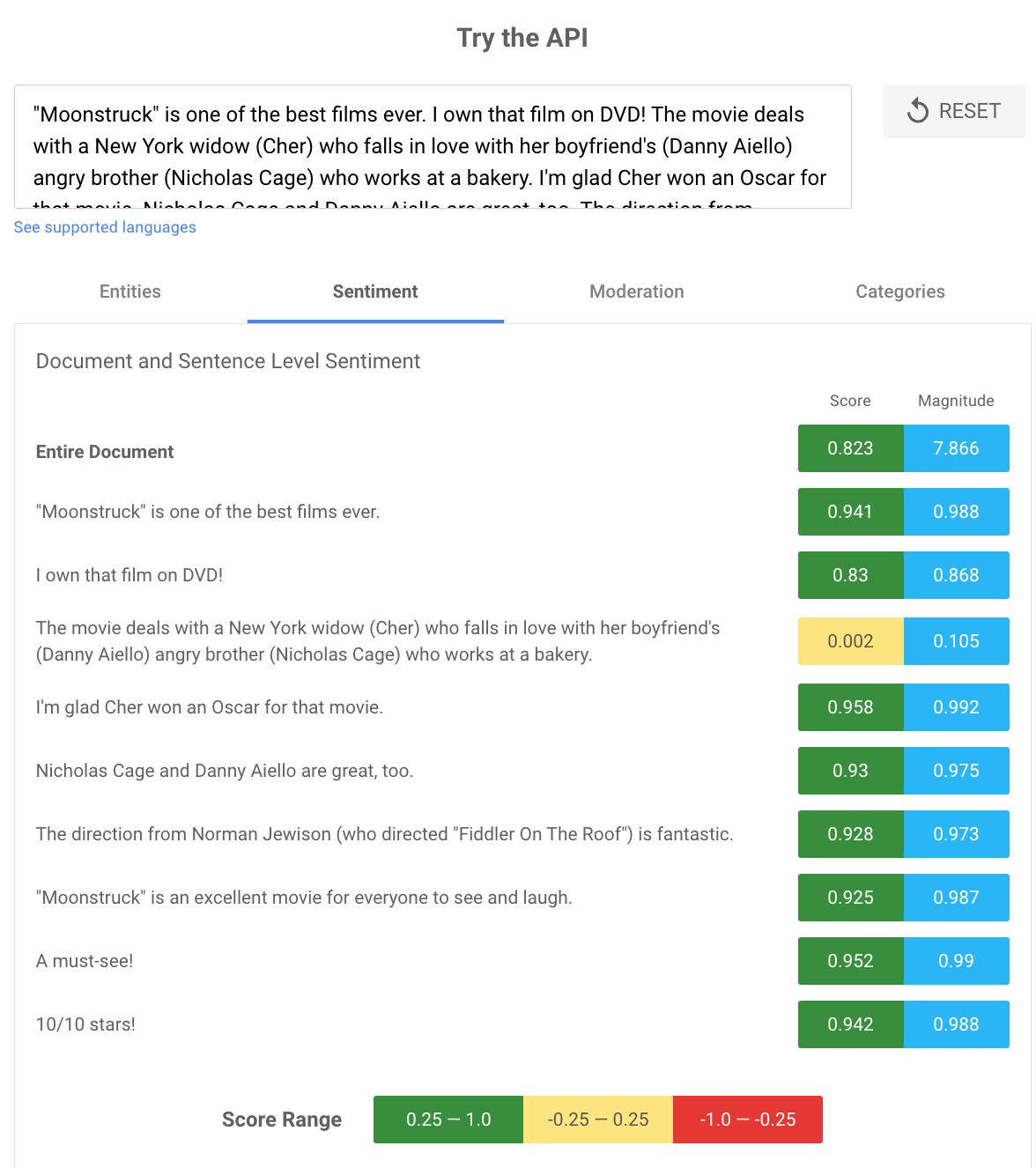
We can see how the NLP API works when we run a 10 / 10 Moonstruck review through the API demo:
Extract sentiment with SQL
CREATE OR REPLACE TABLE `[project].[dataset].[table]` AS
SELECT *, float64(ml_understand_text_result.document_sentiment.score) as sentiment_score, float64(ml_understand_text_result.document_sentiment.magnitude) as magnitude_score,
FROM ML.UNDERSTAND_TEXT(
MODEL `[project].[dataset].[model name]`,
(SELECT review AS text_content, movie_url, label, reviewer_rating from `[dataset].[table]`)
STRUCT('analyze_sentiment' AS nlu_option));Here we run our dataset through the model and save the result in 2 new columns in our table.
A few notes:
- Replace what's in brackets with your own values
- You'll need to rename the column that includes the free text to
text_contentbecause this is the argument name the Natural Language API expects - Here we return only sentiment and magnitude from the model, but the function can return other values as well like language, entities, and sensitive content. The official docs are very useful.
- Cost – This code passes all table rows through the model. In step 1 we sampled the full IMDB dataset to create a table that's only about 50 rows, so this process will be cheap and quick. But using models can get expensive if your table contains thousands of rows or if your code has a bug. To monitor costs I keep an eye on the Google Cloud API dashboard and billing dashboards, and also I use monthly budget and billing alerts which land in my inbox when certain thresholds are hit. But these are all lagging indicators which might not give you signal until it's too late, so it's wise to keep your eye on your console while a query is running.
Sentiment Analysis with Gemini Pro
If you got the code above to run then you're in business and you can access any of the models available in BigQuery. So let's augment our dataset with a result from Gemini, Google's latest and greatest Large Language Model.
-- create a connection to gemini pro
CREATE OR REPLACE MODEL `[project].[dataset].[model_name_b]`
REMOTE WITH CONNECTION `[dataset].[location].[dataset]`
OPTIONS(endpoint = 'gemini-pro');
-- apply a prompt to produce sentiment for each review in our dataset
CREATE OR REPLACE TABLE `[project].[dataset].[model_name_b].imdb_reviews_sentiment` as
SELECT text_content, movie_url, label, reviewer_rating, sentiment_score nlp_sentiment, magnitude_score nlp_magnitude, ml_generate_text_llm_result gemini_sentiment, prompt gemini_prompt,
FROM ML.GENERATE_TEXT(
MODEL `[project].[dataset].[model_name_b]`,
-- the prompt
(SELECT CONCAT('Score the sentiment of this movie review on a scale of 1 to 10, where 1 is hate the movie, and 10 is love the movie. Provide the score as a one digit INT, and provide no other information. This is the movie review: ', text_content) AS prompt, *
FROM `[project].[dataset].[model_name_b].imdb_reviews_sentiment`),
STRUCT(0.2 AS temperature, 3 AS top_k, TRUE AS flatten_json_output));Previously we used the function ML.UNDERSTAND_TEXT but here we use ML.GENERATE_TEXT which lets us perform generative tasks using LLMs. The LLM does the hard work but it requires that we write a clear prompt telling the model what to do. We concatenate the prompt with the free text movie review and send that payload aliased as prompt to the model.
Parameters in the final line can be tweaked to update the entropy and format of the result. But we're looking for a straightforward response so let's try a low temperature of 0.2, and flatten the json response into text.
Once again, be careful of costs. Running this code will process about 50 prompts in 10 seconds and cost about 5 cents.
Evaluating the result
Now we've generated and stored results for all reviews in our dataset. But we're not done yet. We need to sanity check that the AI models produced quality results.
Evaluation is a critical step any time you're working with AI. It's a big part of ML ops, most of which has been conveniently abstracted away for us thanks to Google Cloud. But we do need to do some bare minimum validation to ensure our result meets our threshhold of good enough. So let's see if our results passes the eye test, and then let's do some quick analysis to compare the model outputs vs. ground truth.
The eye test
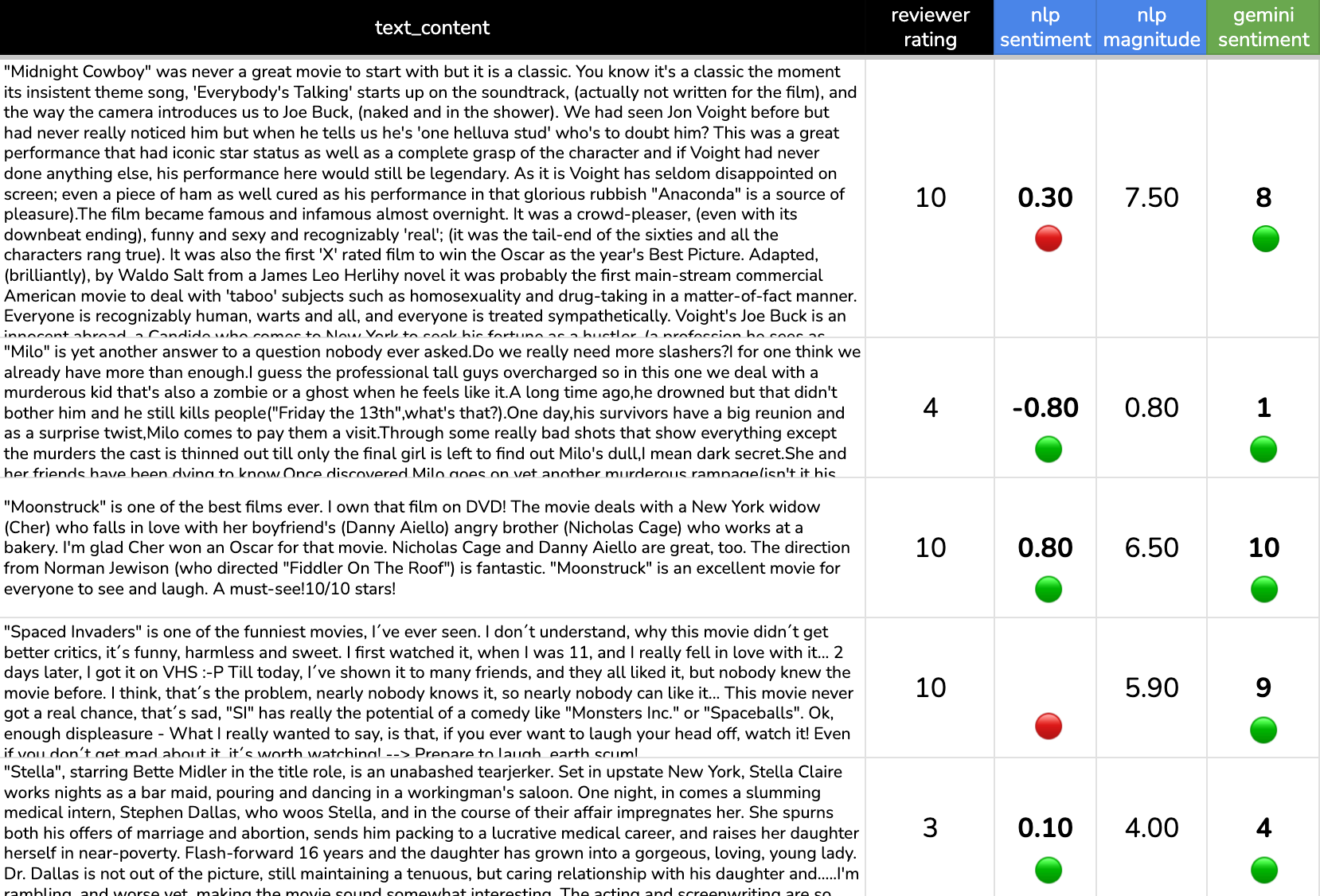
This sample of 5 looks pretty good! We see lots of green when comparing the ground truth rating provided by the reviewer to the results generated by the two AI models. Interestingly, it looks like Gemini might outperform the NLP API which scores the 10 / 10 Midnight Cowboy review with a negative sentiment and also failed to generate a response for the Spaced Invaders review.
EDA
Let's take our evaluation one step further by doing some quick grouping and counting to compare each model's results vs. ground truth. This will tell us which model is the winner. We're gonna do it quick and dirty.
First, we need to normalize results across models so we can compare them. We'll do so with this rubric to label each review as negative, neutral, or positive.
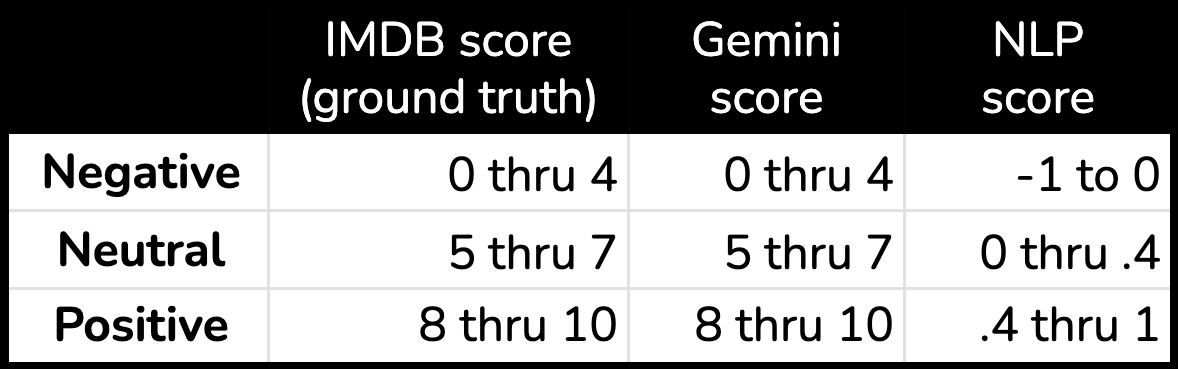
Now that we've got all scores on the same scale we can compare.
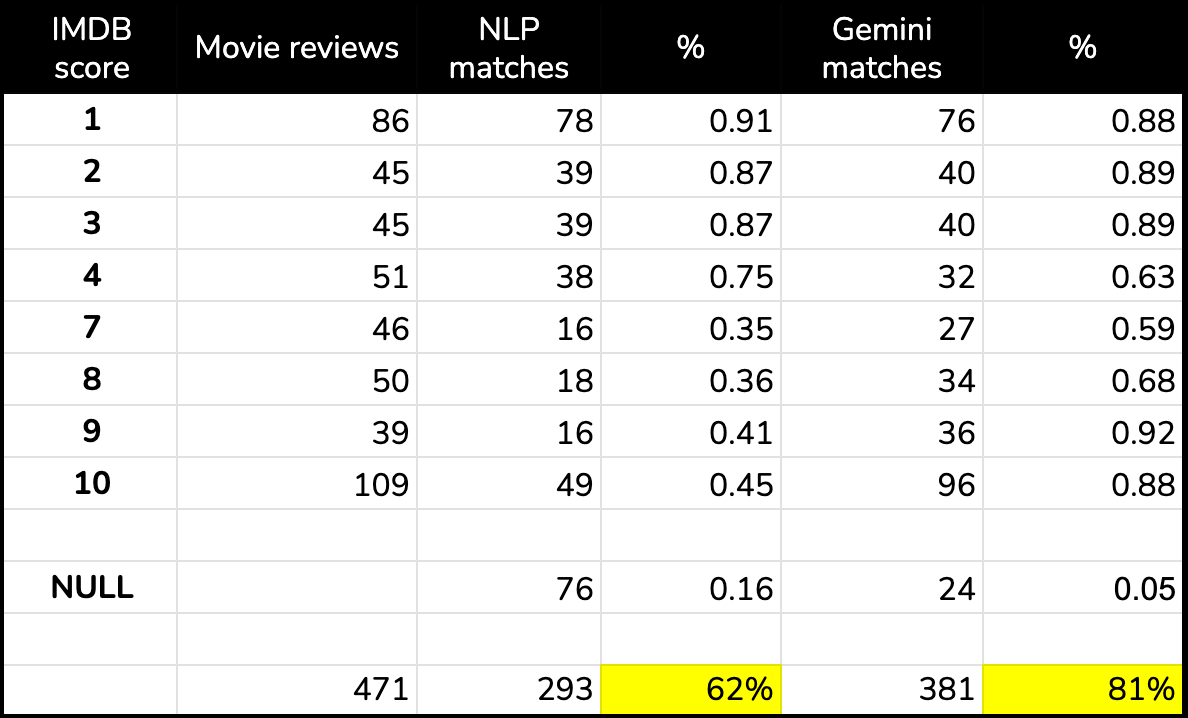
Gemini looks like the winner, with 81% of sentiment labels matching ground truth vs. just 62% for the NLP API.
Caveats apply.
This is an overly simple methodology for evaluating the performance of a machine learning model. There is low hanging fruit if we want to be more comprehensive and statistically sound:
- We probably want to look at sentiment and magnitude returned by the NLP API (we only used sentiment).
- We need to dig into those NULLs (the NLP API result produced 3x as many vs. Gemini).
- And we can try another method to normalize the NLP API results vs. ground truth.
But this is a pretty good start.
Have questions or ideas? Leave a comment or say hi.
Further reading:
 Sam Brand
Sam Brand Sam Brand
Sam Brand Sam Brand
Sam Brand Sam Brand
Sam Brand